Sentence Window Retrieval for Enhanced Context¶
by Grayson Adkins, updated April 10, 2024
This notebook implements sentence window retrieval, an advanced RAG technique for improving the context provided to an LLM at inference time.
![]()
Attribution¶
This notebook is largely based on the DeepLearning.AI course Building and Evaluating Advanced RAG Applications by Jerry Liu of LlamaIndex and Anupam Datta of CMU and TrueEra.
However, in this implementation I make a few changes to the original course material:
- Fixed breaking changes introduced by LlamaIndex v0.10.0
- Migrated
ServiceContextconfiguration to newSettingsobject - Swapped out the existing example data with the much larger collection of Paul Graham's essays, which includes over 500K words. This larger corpus makes the retrieval process even more challenging and gives us more room for improving retrieval with this advanced RAG technique.
Why should you read this notebook?¶
You want to:
- Learn how to improve the generated reponses in your basic RAG pipeline
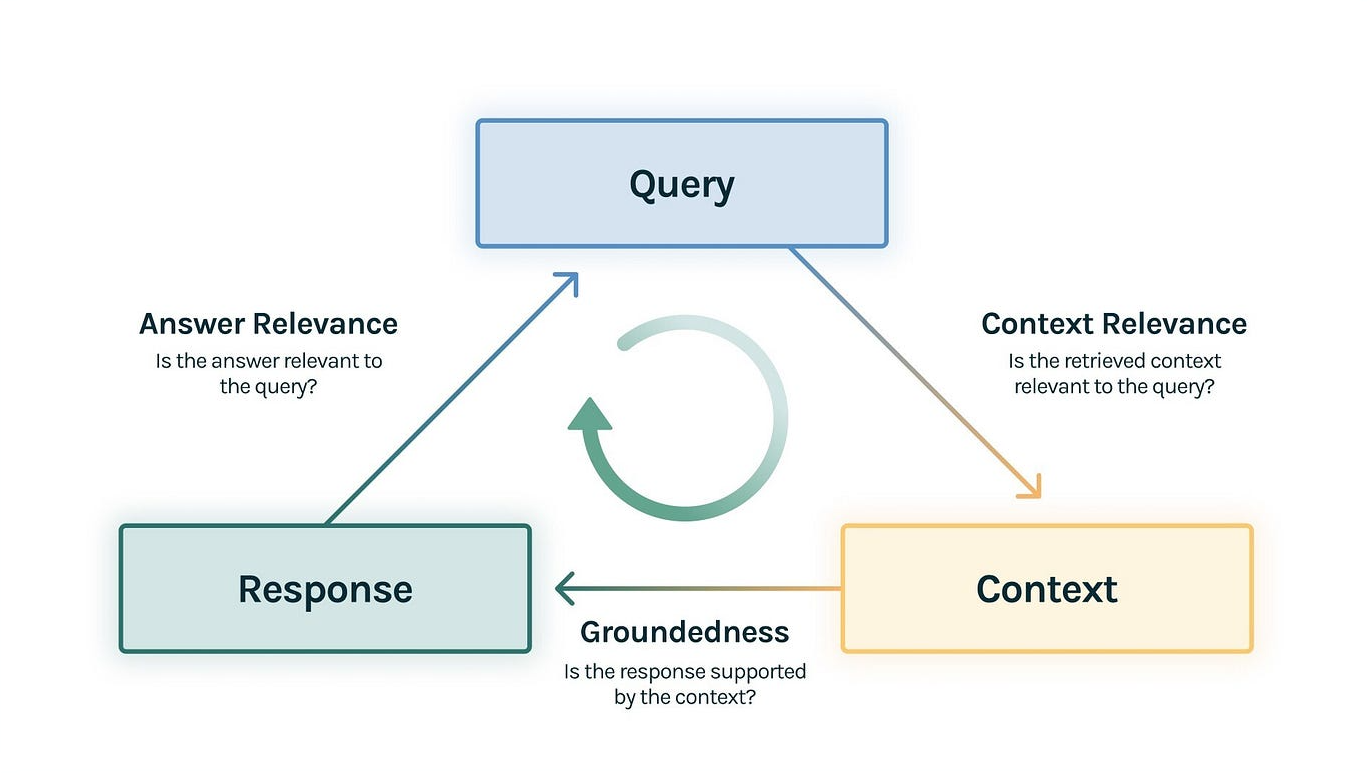
- Have a way to evaluate the relevance of both the retrieved context and generated reponses
- Quantify and visualize experiments as you iterate on your RAG pipeline
Motivation & Main Idea¶
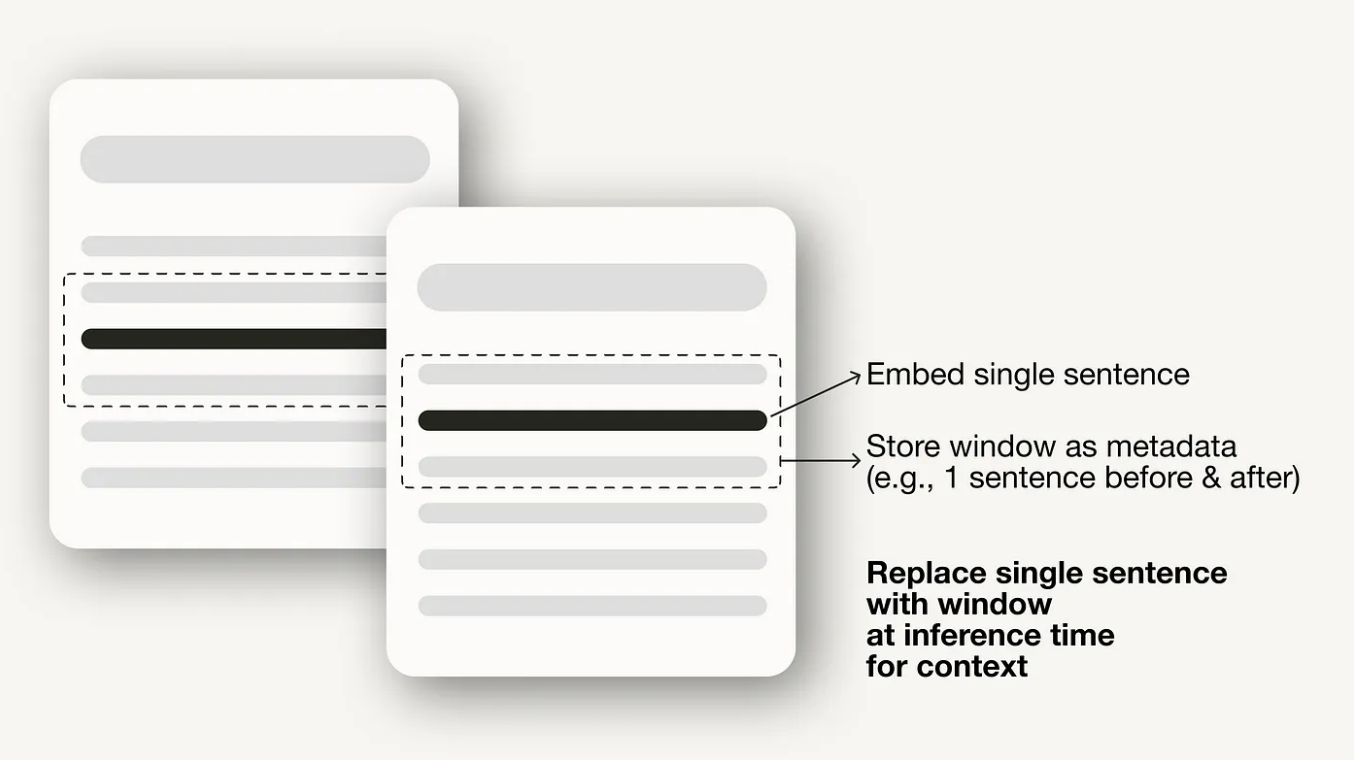
We want to improve upon basic (naive) RAG by improving the context provided to the LLM. Instead of just retrieving the single most relevant sentence for a given query, sentence window retrieval also retrieves the sentences before and after the most relevant sentence. This "window" of sentences will hopefully give the LLM richer context and yield better generated responses.
Summary of Results¶
In this notebook we demonstrate that sentence window retrieval improves Answer Relevance by 22.7% and Groundedness by 38.2% compared to a basic (naive) RAG process, while also reducing the total number of tokens generated. We find that Context Relevance remains more or less unchanged from the basic RAG pipeline.